
Het AI nieuws van week 28

Het moment waarvan je wist dat het zou komen... deze nieuwsbrief is niet (ik herhaal niet!) langer dan de vorige!!
Dit is mijn laatste gewone nieuwsbrief voordat ik op vakantie ga, voor volgende week en de weken erna ga ik een speciaal zomerserietje doen! Korter en met meer achtergrond, lekker voor op het strand. Na begin ik in september weer op de gewone wijze. En deze is dus al korter, want ik ben al vanaf donderdag op een weekje fietsvakantie! Fijn voor wie nog drie ongelezen mega-exemplaren in de mailbox heeft (ik hoor deze klacht regelmatig als ik in de echte wereld lezers tref, dat ze nog niet helemaal bijgelezen zijn...).
Deze nieuwsbrief bereikt je dus zonder dat ik op de knop heb geklikt vandaag. Zeg niet dat ik niet van technologie hou, want terwijl ik op weg ben naar Den Helder voor een rondje Texel op de fiets morgen, vliegt deze nieuwsbrief volautomatisch je mailbox in!
Over nieuwsbrieven...
En... mijn nieuwsbrief bestaat deze week een half jaar, hoera! Ik begon er in week 3 mee, dus ik heb er precies 26 getikt. Tijd om eens na te denken dus over het fenomeen nieuwsbrief. In een stuk dat ik wel gebookmarked had, maar (denk ik, ik onthoud ook niet alles) nooit eerder gedeeld, becijferde New York Times dat we wel 3000 dollar uitgeven aan nieuwsbrieven! Ik vind het stuk trouwens ook niet bepaald goed, het is een slappe aanklacht tegen mensen die er veel geld aan uitgeven, en dat komt volgens het stuk omdat mensen niet goed bijhouden waar ze zich allemaal op abonneren. Dat kan waar zijn, maar ik denk dat er ook nog iets heel anders speelt.
Ik denk dat de populariteit van nieuwsbrieven (en misschien ook, van podcasts) aantoont dat mensen in de basis gewoon graag connectie voelen met andere mensen. In het hele hele vroege internet, laten we dat het blogoceen noemen, maakten mensen hun eigen website op simpele platforms als geocities, friendster en myspace. In die tijd had zo'm platform een hele andere rol dan nu...
Je was geen influencer, je was gewoon jezelf.
Mensen vonden je website omdat ze jou al kenden, of omdat ze in de echte wereld getipt werden over je site. Je werd maar zelden met een zoekmachine gevonden, best case stond je site op een blog- of webring onder één of ander thema. Je had misschien een klein beetje kennis nodig om toen een website te maken, maar niet heel erg veel.
Na het blogosceen kwamen we in een nieuwe fase, het algoceen, waarin mensen zich (vrijwillig, geschiedschrijvers zullen zich het hoofd breken over waarom) verplaatsten van een space in eigen beheer, maar een plek waar ze alleen nog maar content schreven. Ook ik stapte vrijwillig van mijn eigen blog die ik lang had, naar Twitter. Niet helemaal natuurlijk, ik behield mijn blog wel, en ik schreef er ook nog op, maar ik schreef ook een hele hoop slimme en grappige dingen op Twitter; want het vroege Twitter voelde niet anders dan het vroege internet, een plek waar mensen elkaar volgden. Het was zelfs nog leuker en menselijker want omdat het laagdrempeliger was—voor 140 karakters hoef je niet echt te gaan zitten—dus je kreeg echt een beeld van de persoon aan de andere kant (dit had ook nadelen...). In het begin was er ook geen algoritme om te gamen, je volgde mensen die je kende, en je netwerk breidde zich steeds uit. Maar toen kwam de algoritmische tijdlijn, en verwerden we langzaam van mensen tot contentmachines. Wasmiddel eten voor de kliks, ijswater op je kop, like and subscribe, I am humbled to announce, het internet werd een podium, waar we niet meer met elkaar praten maar tegen elkaar. En net als op een podium, zag je je publiek niet echt meer als losse mensen maar als een zee van koppies, of helemaal niet.
Ik zeg vaak bijna alles dat in de wereld bestaat, is een reactie op iets anders, en in dat licht moeten we nieuwsbrieven ook zien, als een tegenbeweging. Niet als iets waar mensen per ongeluk op klikken, maar juist als een terugkeer naar de menselijke connectie. Een nieuwsbrief is als een oude blogpost, of een echt goed draadje op Twitter, het vertelt een verhaal en geeft een inkijkje in hoe iemand denkt. Het format zet aan tot nadenken, en je kan met een nieuwsbrief niet echt viral gaan. Alles wat het algoritme probeerde te doen, wordt met het nieuwsbrief-format ongedaan gemaakt. En het mooie is, we gebruiken een van de laatste stukjes vrije en open technologie: email!
Had Google Google Reader niet vermoord en daarmee de laatste spijker in de doodskist van RSS feeds sloeg, dan hadden we nieuwsbrieven misschien wel in een handige lees-app verzameld. Jammer van RSS, ja, maar wij zijn niet te stoppen! We hebben email: toegankelijke, simpel, compatible met allerhande apparaten en systemen, en in theorie buiten de macht van big tech te consumeren[[1]]. De vrijheid van het internet in actie, het is hoopgevend!
Analyze van een (t)aal
Ik hou van lezen, ik hou van schrijven en ik hou van taal. Het mooie aan taal, zo anders van programmeren is dat je alles kan doen, wat je maar wil! Je kan bijvoorbeeld woorden verzinnen, en als je die goed uitlegt, of als je lezer genoeg context heeft, dan kan dat gewoon!
In mijn vorige nieuwsbrief bijvoorbeeld gebruikte ik een metafoor van een gladde aal die probeert uit een pot van een of andere gladde substantie te ontsnappen die verantwoordelijkheid vertegenwoordigt. Ik moest er om glimlachen toen ik het schreef en ik lach er nu weer om! Maar toen ik het schreef, twijfelde ik over de nog tussen tussen "verantwoordelijkheidsolie" en "verantwoordelijkheidsboter".
Dus ik dacht, even een Googletje aan wijden, alsof het nog 2024 is. Is een aal in de olie, of een aal in de boter, iets dat iemand ook al eens geschreven heeft? Maar natuurlijk, het is 2025, en de AI glibberde zo de zoekresultaten in...
Ik weet het, dit is een piepklein en een totaal niet belangrijk zoekopdrachtje, maar toch! Ik wil het fileren, omdat het zo tekenend is voor de hele ellende.
Ten eerste omdat ik helemaal geen AI besteld had, ik wilde alleen maar zien of deze term ergens stond, op een site, in de echte wereld.
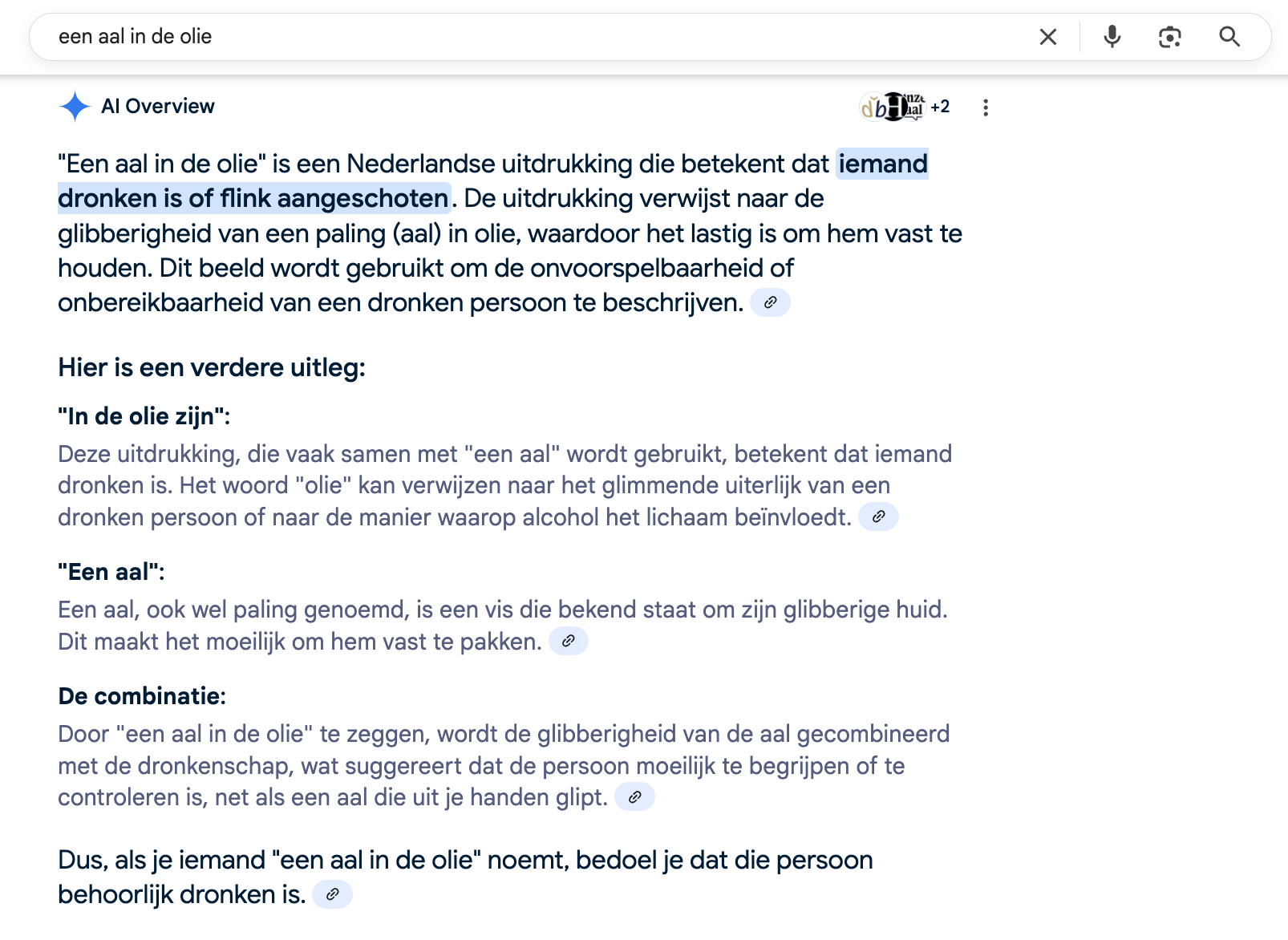
En dan krijg ik niet alleen gehallucineerde onzin, maar het ziet er ook nog eens onderbouwd uit! Met die bronnen erbij! Maar, kom, humor me, laten we eens kijken wat er eigenlijk op die links staat. Als we op het eerste link-icoontje klikken, klappen er vier uit:
- DBNL entry over Nederlandse spreekwoorden, nummer 1662 over de uitdrukking "in de olie zijn", maar niets over een aal.
- historiek.net, historie van "in de olie zijn". Ook niks over een aal.
- Onze Taal, uitleg over de uitdrukking "glad als een aal". Maar niks over olie.
- Ensie, weer over de uitdrukking "in de olie zijn". Geen aal te bekennen.
Er staat dus nergens, op geen enkele van deze bronnen die achter "een aal in de olie" staan, iets over een aal in de olie.
Maar goed, dit is het eerste bron-icoontje. maar bij het kopje De combinatie zal toch wel wat over de combinatie van aal en olie staan toch, toch, toch?
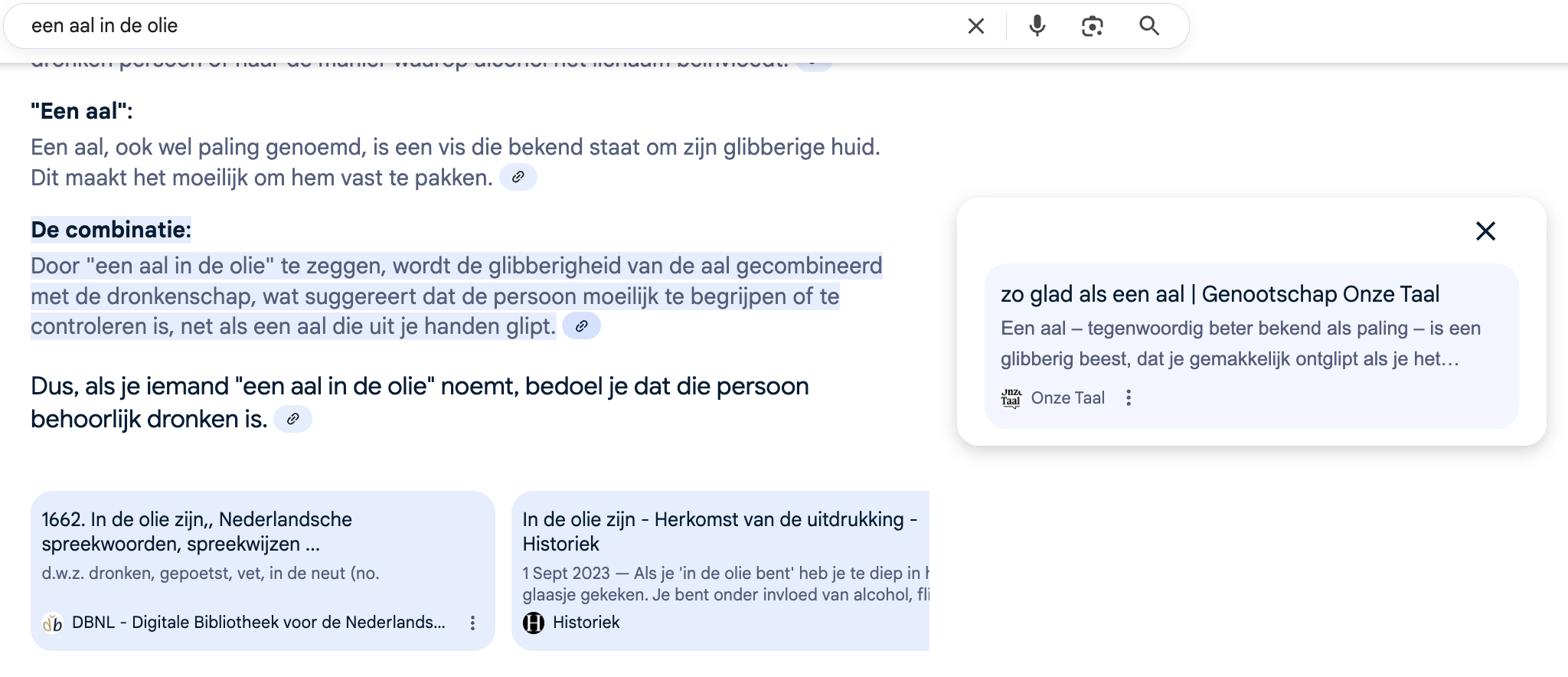
Nee hoor, die gaat gewoon nog eens de totaal olievrije pagina van Onze Taal. Zo dat weer eens 30 minuten van mijn leven verloren aan die ellende. Doe ik graag natuurlijk om mijn punt te maken, het leven is content als nieuwsbrieftyper.
Maar dit is wel waarom ik zo boos word als mensen zeggen dat je de informatie uit chatbots "gewoon even moet controleren". Controleren is enorm veel werk, en bovendien het vergt al een enorme basiskennis. Ben je een beetje een slordige lezer, heb je haast, of ken je niet alle Nederlandse spreekwoorden, dan trap je er toch zo in! En bovendien, waar moet je nog controleren nu het hele internet slop wordt, een woordenboek of encyclopedie?? Zie ook mijn stuk in NRC in maart. Als AI niet een zonder problemen het alfabet kan uitschrijven, hoe controleert dan iemand nog iets?
Maar er is nog veel meer aan te merken op deze situatie dan alleen de burden die verschoven is van de lezer naar de zoekmachine om zelf maar ff te kijken of het klopt. Het tonen van die bron-icoontjes door de tekst heen, maakt het geheel wat mij betreft namelijk slechter en niet beter. Het is een designkeuze om de links te tonen, en dat is ongetwijfeld een reactie op klachten dat AI resultaten niet te vertrouwen zijn. Kijk maar, alles klopt hoor, ik heb de bonnetjes nog!
Maar in de designkeuze van Google die hier link-icoontjes over de zoekresultaten sprinkelt, zien we twee kern-problemen terug die in de informatica-cultuur steeds maar weer naar boven komen: een desinteresse in nadenken over hoe mensen technologie interpreteren, en een gebrek aan epistemologische kennis.
Want wat zou een redelijk mensen denken als die zo'n linkje ziet? De semantiek van een link-icoontje, dat lijkt op bijvoorbeeld de bronvermelding op Wikipedia, geeft een bepaald gewicht dat Google helemaal niet waarmaakt. Wat zo'n citation namelijk betekent in de ogen van een gewone internetgebruiker, is dat iemand een tekst gelezen heeft en heeft afgetekend dat wat er in de zin staat, ook door de bron onderbouwd wordt. En dat is hier totaal niet aan de hand. De link-icoontjes geven het antwoord dus een vernisje van echtheid, door een signifier te gebruiken die wij mensen zijn gaan relateren aan kloppende connectie. En hop, de twijfel die je misschien zou kunnen krijgen door al die lelijke AI-klagers (die zeuren maar, deze week weer over hallucinaties van een brandweer-app in California), zo, uitgewist!
Iemand die interesse heeft in diep nadenken over hoe mensen dingen interpreteren, zou kunnen reflecteren op het toevoegen van zulke tekens. Welke epistemologische indruk geeft een bronvermelding? Wat voor soort kennis denkt de lezer dat hier staat? Voor de compulsive programmer, die houdt van dingen bouwen en de werkelijkheid buitensluiten, is dat soort geneuzel echter totaal niet aan de orde, het klopt toch? Hoezo "wat voor soort kennis?" wat betekent dat? Dat ís toch een bron op basis waarvan we het antwoord hebben gegenereerd? Wat de mensen er verder van denken, ach dat is mijn probleem niet!
Het laat ook echt zien hoe informatici omgaan met bronvermelding in het algemeen; bronnen controleren, terug gaan naar de originele tekst, dat leer je niet op een technische studie. Bronvermelding is een soort noodzakelijk kwaad waarin je voornamelijk met bronnen omgaat om je er tegen af te zetten: Wat Pietje eerder heeft bedacht? Dat doen wij beter!
I know dit was toch nog een lang verhaal over een aal, maar het doet er echt toe hoe 's werelds grootste zoekmachine kennis representeert!
Wiens software, wiens AI?
De verwevenheid van programmeren en politiek, ik had het er vorige week nog over, en onlangs werd in geïnterviewd voor de leuke podcast Computer says maybe. In de podcast leg ik uit dat ik aanvankelijk dacht dat de inclusiviteitsproblemen van de informatica gewoon een klein foutje waren. Iedereen was gewoon eventjes vergeten om programmeertalen ook in het Spaans, Arabisch, of Chinees te maken. Maar gaandeweg kwam ik er achter dat het echte probleem de cultuur van programmeren is, en die is veel weerbarstiger dan het ingewikkeldste stukje code. Veel mensen denken, impliciet of expliciet dat programmeren in het Engels moet, of hoort. Dus dan kan je wel een anderstalige omgeving bouwen, maar dat verandert dan niet veel.
Die verwevenheid van software en menselijke keuzes komt overal voor; het gaat niet alleen over vrouwen of mensen uit de niet-westerse wereld, al zijn die natuurlijk wel vaker de klos, het gaat uiteindelijk over de keus tussen automatiseren en menselijkheid. Alle automatisering gaat altijd ten koste van een mens die een ander mensen ziet, letterlijk en figuurlijk. Dat kan de moeite waard zijn, maar je kan het niet ontkennen. Als ik deze nieuwsbrief als een fysieke brief met de hand zou schrijven en opsturen naar je huis, of voorlezen onder je raam, dan was het een heel ander iets. Zou een hoop meer werk zijn, maar ook mooier en menselijker.
En soms is de ontmenselijking zo on the nose dat je denkt... Kan dit echt? Zo las ik afgelopen week een stuk in de Guardian over Tesla, over allerhande lelijke praktijken (bijvoorbeeld data achterhouden), maar als ergste dat Tesla-auto's snel de autopilot uitzetten vlak voor een crash. Want, dan staat er in de data van de auto dat het ongeluk gebeurde terwijl de autopilot uitstond, dus.. de chauffeur zelf is de schuldige.
Dit is toch sjoemelsoftware to the max?! Sjoemelsofware, weet je nog? Het was het woord van 2015! Het was toen echt een grote zaak, een van de programmeurs die had meegewerkt aan de code werd zelfs veroordeeld tot 40 maanden gevangenisstraf. Net als bij Cambridge Analytica was ik toen naïef genoeg om te denken dat dit een soort awakening teweeg zou brengen, dat iedereen zou zien hoe in en in slecht softwarebedrijven zijn, en hoe ze enkel en alleen op winst gebrand zijn, maar nee hoor. Schouders ophalen en doorleven. Sindsdien ben ik niet meer zo naïef meer dat ik denk dat mensen en masse kritisch gaan worden, maar ik blijf het zelf wel.
Het is dan ook droevig, maar totaal niet verrassend voor mijn dat iedereen en zijn grootmoeder keuzes en waarden die altijd in software zitten, totaal negeert. In tegendeel, we hebben het wel over AI die neutraal is, soms nog neutraler dan een mens, maar bestaat helemaal geen neutraal. En dan heb ik het niet eens over hoe makkelijk we een AI "van de rails" kunnen laten lopen!
Ik heb het veel meer over het idee dat in een LLM diep-verankerde culture aannames zitten. Mooi onderzoek van het Ada Lovelace Institute laat zien dat er hele grote verschillen zijn tussen hoe mensen en LLMs reageren, en dat die verschillen groter zijn naarmate een land verder van de VS af staat.
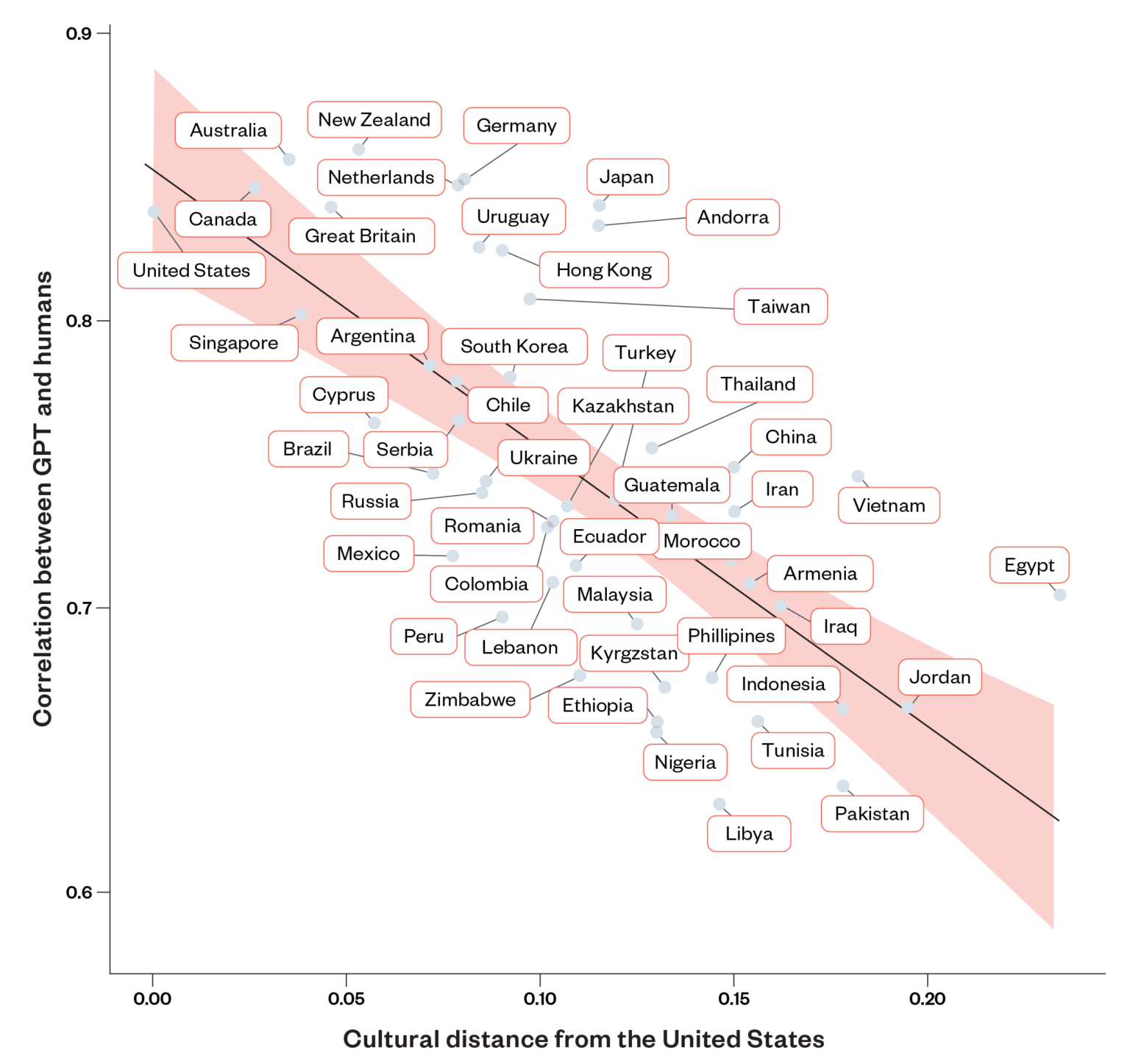
Nu kan je dit natuurlijk geen probleem maar een oplossing vinden, mooi, straks heeft de hele wereld onze Westerse, kloppende, mening! Er zijn altijd mensen die er zo over denken. Maar zélfs als je dat denkt, kan je met zulke resultaten toch niet ontkennen dat een LLM een bepaalde smaak heeft, en dus niet neutraal is.
Daarom raakt het me ook dat de NRC met LLMs gaat "experimenteren", want zo zeggen ze, we kunnen het toch niet verbieden want dat is niet te controleren, en misschien zijn er wel voordelen:
"Volgens ons is de enige uitweg uit deze patstelling: experimenteren dan maar. Alleen door een techniek te gebruiken – voorzichtig, tastend, maar ook nieuwsgierig – kunnen we zien hoe we AI kunnen en willen gebruiken, en hoe niet. "
We moeten het maar blijven zeggen: gebruik is niet nodig om te weten of je iets wilt gebruiken. Zoals ik al eerder schreef, ik hoef geen olieraffinaderij in de tuin om te weten of ik benzine in mijn auto wil gooien. Je kan je prima verhouden tot iets zonder het te gebruiken, er de redenen om AI niet te gebruiken zijn er voldoende, vanuit klimaat, cultuur- en gendergelijkheid, deskilling en ga zo maar door. Wil je die niet meenemen in je overweging, dat mag. Maar dat je dat als enige uitweg ziet zegt wel alles over wat (en wie) je belangrijk vindt. Het is echt een teleurstelling dat de NRC zo de oortjes laat hangen en big tech de agenda laat bepalen.
Biesta & AI
Op 12 juni was ik bij een geweldige lezing van Gert Biesta, die tegelijkertijd wel en niet over AI ging, en wat heb ik daar van genoten! Heb je dus nog tijd in de zomer, dan is het echt de moeite waard. Het is een soort tegenovergestelde van een evidence informed verhaal, in de beste zin van het woord; Biesta geeft geen antwoorden, maar stelt vragen, legt spanningen bloot en zet aan tot nadenken over wat onderwijs eigenlijk is. Ik wil er nog heel lang op broeden.
Vooraf leidde Remco Pijpers van Kennisnet (en ook VU-promovendus) in, en na afloop mocht ik met hem, Luc Sluijsmans en Ruth van de Vrede-Van den Born napraten in een panelgesprek.
Weg van big tech betekent er anders naar kijken
Een tijdje terug al, maar mis dit mooie interview met Nicolas Carr toch niet in de Groene Amsterdammer. In het stuk benadrukt hij hoop voor de toekomst, in de vorm van een tegenbeweging van jongeren:
"Als er een tegencultuur ontstaat zoals in de jaren zestig, waar jongeren zeggen: deze technologie is dominant, het controleert, surveilleert en onderdrukt ons, het is iets dat volwassenen gebruiken, maar wat wij afwijzen"
Dat zou mooi zijn, en misschien wel de enige manier, dat jongeren in verzet komen.
Ergens zie ik dit ook al wel in de praktijk, leerlingen in mijn klas zouden nooit zonder jouw toestemming een foto van je op Insta zetten, mensen van mijn leeftijd en ouder doen dat zonder nadenken.
En ja, sommige mensen, jong en oud, gaan terug naar de dumbphone, wie weet komen we er toch! Stoppen met je telefoon, het is echter zo makkelijk nog niet... Ik hou het zelf goed vol, maar ik snap zeker de overwegingen van Merijn Doggen van de Universiteit van Nederland die er na een week al de brui aan gaf. Want ik geef eerlijk toe: voor mijn man is het onhandig dat ik geen smartphone meer heb. Fotootje airdroppen? Kan niet, moet via de mail of met een kabeltje. Toegangskaartjes? Ja die moeten op zijn telefoon of geprint. Signal/appje sturen dat je te laat bent? Kan niet, moet via sms.
En ik ben dan wel van mijn iPhone af maar ik heb nog wel een iPad en een Mac, dus het ecosysteem van Apple heb ik nog niet verlaten. Je ziet hoe sterk het netwerkeffect is: je wil je op de platforms begeven waar je vrienden en familie ook op zitten, anders mis je toch dingen.
l'ordinateur portable, mais non!
Weg met de laptop in de collegezaal, dat zeg ik natuurlijk al langere tijd, maar heel misschien begint het tij een beetje te keren...? Een mens mag dromen, toch?! Op een aantal Franse universiteiten moeten de laptops dicht blijven! Anders zitten studenten maar online te shoppen, of te scrollen op social media. En zo is het, studenten (en volwassenen ook trouwens!) vinden het gewoon veel te moeilijk om zich goed te concentreren met dat ding open. We zouden deze regel ook voor vergaderingen moeten invoeren, of we praten goed met elkaar, of we zijn samen in een ruimte aan het emailen, ook leuk maar dat kan dan weer efficiënter als er niemand doorheen praat.
AI in de zorg
De kogel is toch nog door de kerk, kort voor het zomerreces, het zorgakkoord is er! Maandenlang gedoe met Agema, maar hoi hoi hoi, nu krijgen we 400 miljoen voor de zogeheten doorbraakmiddelen, geld om de zorg effiënter te maken, niet door meer personeel of betere proceduren, nee! Met AI natuurlijk. Misschien leest Agema mijn nieuwsbrief ook en is dit een dikke knipoog... want dankzij deze 400 miljoentjes kunnen de LLMs lekker door-braken!
Nee, Hermans, niet zo flauw doen, AI in de zorg is meer dan alleen maar generatieve AI. Met ouderwetse AI, zoals beeldherkenning, kunnen we echt sneller betere zorg leveren, bijvoorbeeld om radiologen te helpen! Radiologie is een favoriet onderwerp, waar zo'n 80% van de medische inzet van AI plaats vindt.
Ah, ja goed punt, ik vraag het even na aan Henk Marquering, hoogleraar radiologie bij de UvA. Hij benoemt in zijn oratie de kloof tussen hype en praktijk, en noemt een uit onderzoek naar 200.000 scans dat de effectiviteit van een ingewikkeld (en duur) softwarepakket om radiologen te helpen analyseerde.
Wat bleek uit het onderzoek...? De nieuwe software leverde maar 11 minuten (!!!!) tijdswinst per maand op. Desondanks blijven de hype-verhalen ons natuurlijk om de oren vliegen, bijvoorbeeld in de Guardian, waar Microsoft mag vertellen over hoe o3, een nieuw model van openAI, maar liefst 8 van 10 case studies correct kan diagnostiseren, beter dan menselijke dokters, die hebben er maar 2 van de 10 goed. Lees je even verder (niet eens zo heel ver, het is in de derde paragraaf) dan zien we dat 1) de 10 case studies speciaal dit onderzoek waren uitgekozen uit een set van 300 en ook nog eens aangepast, en 2) de dokters waartegen vergeleken werd geen enkele hulpbron mochten gebruiken. Ja, zo kan ik het ook met je superintelligentie, hoe deed je algoritme het dan op de andere 290? En alsof een dokter bij een complexe case geen handboek erbij zou pakken!
Zonder verdere vragen of tegenspraak mag hoofd AI van Microsoft vertellen dat:
"It’s pretty clear that we are on a path to these systems getting almost error-free in the next 5-10 years. It will be a massive weight off the shoulders of all health systems around the world"
Hoe vaak moeten we dit soort dingen nu nog horen? Al een decennium voorspelt George Hinton dat radiologen binnenkort niet meer nodig zijn, en dat klopt niet en veroorzaakt nu al tekorten. Hoe kan het toch dat een journalist dát niet noemt in een interview?
De publieke ruimte van onze dromen
In week 13, tsjonge dat lijkt al lang terug, had ik het over een mooi voorbeeld van een veranderende publieke ruimte, en hoe mooi het kan zijn als er meer ruimte komt voor mens en natuur en minder voor de auto.
Nu is er in Berlijn ook weer een schitterend voorbeeld (auf Deutsch, maar prima te volgen) van een hondermeterlange autovrije strook bij een school. Treffend ook om te zien dat iets dat bedoeld is om kinderen veilig te houden, ook voor andere aardbewoners fijn blijkt.
"Dabei profitieren nicht nur SchülerInnen von weniger Lärm und mehr Bewegungsfreiheit: 'Seit die Straße vor ein paar Wochen für den Autoverkehr gesperrt wurde, erleben wir, dass die Fläche auch nachmittags und abends gut angenommen wird', sagt Jane-Goodall-Schulleiterin Kathrin Rohwäder. 'Hier treffen sich Familien und auch Teile der Schulgemeinschaft.'"
En ook in Washington gaan ze proberen auto-vrije straten in te voeren, wat nog ingewikkeld was omdat er blijkbaar een staatsbredewet gold die een minimum-maximumsnelheid voorschreef van 20 mile per uur(= 30 km/uur). Die moest eerst van tafel, maar dat is nu gelukkig gebeurd, dus kunnen ze ook in Washington state gaan genieten van fietspaden.
Deze buitenlandse interesse in voet- en fietsinfrastructuur deed me denken aan mijn favoriete stukje onbekende vaderlandse geschiedenis: actiegroep "Stop de kindermoord", die de veilige straten hebben bedongen waar we nu allemaal van profiteren. Ook nu nog wordt weer bewezen dat in straten waar je maar 30 km/u mag, minder ongelukken gebeuren.
Zo zie je, meestal komt verandering niet tot stand doordat de overheid op een dag verstandig wordt, maar door burgerlijke actie, vaak met een fikse dot ongehoorzaamheid want ook Stop de Kindermoord blokkeerde wegen!

Vibe coden
Zonder smartphone leven is goed te doen tot nu toe, maar ik miste mijn audiobooks enorm, en mijn Light Phone ondersteunt wel muziek, die je kan uploaden, of podcasts die je (oa) kan beluisteren door je op een rss-feed te abonneren, maar geen audiobooks. Voor iemand die een weekje alleen op fietsvakantie gaat, is geen audiobooks eigenlijk niet te doen, je kan maar zoveel Ed Zitron aan op een dag...
Dus, had ik bedacht, ik kan zelf een mp3tje ophakken, uploaden op mijn eigen server, een rss-feed bakken met linkjes naar die files en me daarop abonneren! Hoppa!
Daar toen moest ik wel allerhande kleine scripting-klusjes uitvoeren, zoals de file ophakken, en een XML-bestandje maken om als RSS-feed op te abonneren. Dat was ergens ook een leuk klusje, want het gaf me echt het gevoel dat ik de macht over mijn eigen machines weer aan het terugwinnen was!
Maar, ik probeerde natuurlijk ook even vlotjes wat te vibe coden, want een syntactisch valide rss-feed maken kan ik ook niet uit mijn hoofd, en ik wilde dat het een beetje opschoot. Narrator: Het schoot voor geen meter op.
Ik kreeg een stukje code, het runde ook nog eens maar de RSS-feed die eruit kwam, was ongeldig omdat sommige verplichten argumenten misten. Toen ging ik aan de code schaven, en nog wat, en nog wat, tot ik tot de conclusie kwam dat het toch echt sneller was om het zelf te doen, zelfs gezien de tijd die ik al verloren had aan viben. Deze ervaring blijkt niet uniek, op Linkedin schreef programmeur Shanea Leven hetzelfde, zij noemt het de "we zijn er bijna-val":
"AI gets you to 70% fast. Then you spend 3x longer fighting the last 30%. Because every fix breaks something else but you end up rewriting anyway."
En dat is niet alleen maar even haar eigen ervaring. Gary Marcus beschreef een recent onderzoek waarin open source developers in een randomized control trial Ai gingen gebruiken. Voor iedere taak die developers toch al van plan waren om uit te gaan voeren werden ze random ingedeeld om dat met of juist zonder AI te doen. Boeiend was niet alleen de uitkomt, maar ook de verwachting van de developers zelf, ze zeiden vooraf dat ze dachten dat AI ze 24% productiever zou maken, en achteraf dat AI ze 20% productiever gemaakt had.
Maar wat bleek? Mét AI waren ze juist 19% langzamer! Veel tijd (9%) ging naar het fiksen van fouten in AI output. Geen verrassing maar wel goed dat het gemeten wordt. En, zo vermeldt het paper, een andere factor is dat:
"AI doesn’t utilize important tacit knowledge or context"
Dat past weer bij wat ik vorige week schreef: het moeilijke van programmeren is niet de code, maar de context! En hoe beter een developers wist wat hij of zij ging doen, hoe langzamer ze werden, waarschijnlijk (dat zeg ik, dat staat niet zo in het paper) omdat ze meer eigen kennis hebben om te tegen te vergelijken. Een van de deelnemers zegt wel dat als je al veel weet, AI gewoon niet meer helpt:
"if I am the dedicated maintainer of a very specialized part of the codebase, there is no way agent mode can do better than me."
Dus wie trapt dan wel in die "bijna goed val"? Junior developers zonder veel ervaring, zo schrijft Sean Carolan, want die zien de fouten niet.
"Junior coders and people who don't write code at all lack the context to correct the AI when it goes off track."
Zeker, en, zou ik daar nog aan toe willen voegen, ze missen ook het 1) zelfvertrouwen dat ze altijd nog terug kunnen vallen op good old met de hand typen, en 2) de basiskennis van processen om tot een oplossing te komen.
Toen ik vastliep op de ongeldige XML-files, begon ik minimaal: bouw een RSS-feed met niks erin. Ok, dat werkt. Nu met eentje erin. Ok, dat werkt. Nu een grotere MP3, ai, dat loopt vast! Maak het de helft kleiner. Ow, dat loopt ook vast. Hmmmm, misschien is er een ander probleem! Aha, mijn nieuwe files gebruiken http en geen https, misschien is dat het.
Om de laatste 20% te fiksen moest ik een hoop dingen meer weten, en moest ik durven de LLM los te laten om het zelf te doen. Maar nu kan ik dan wel lekker Cory Doctorow (Little Brother) en John Boyle (A ladder to the sky) luisteren! Misschien komen ze wel langs in de zomeredities van mijn nieuwsbrief die ik nog moet verzinnen, maar die zeker ook een boekentip gaan bevatten!
Slecht nieuws
Slecht nieuws vinden was weer geen grote uitdaging voor deze editie. De mazelen zijn terug van weggeweest in de VS, en met 1281 gedocumenteerde gevallen tot nu toe, op het hoogste niveau sinds 2000. Waren er in 2024 nog 16 uitbraken, dat zijn er nu al 27. Het is wachten op een mutatie die bestaande immuniteit doorbreekt en dan hebben we weer een lekkere pandemie te pakken.
Zit je op Spotify? Dan word je misschien wel blootgesteld aan AI muziek, al een half miljoen luisteraars gingen je voor! Geen probleem misschien als je echt gek bent op AI muziek (zou kunnen, smaken verschillen!), maar in dit geval was het voor fans van de band The Velvet Sundown helemaal niet duidelijk dat het AI is.

Het is een goed voorbeeld van AI die taak overneemt die mensen leuk vinden, ipv saaie taken als de was doen. Ik wacht nog steeds met smart op een robot die mijn vaatwasser uitlaadt!
Onderzoek van Stanford laat zien dat dat eerder regel is dan uitzondering. 41% van de AI bedrijven in startup-community Y Combinator (je weet wel waar sam Altman de scepter zwaaide voor hij naar OpenAI overstapte) automatiseren taken die mensen helemaal niet willen overdragen aan een AI! Zij noemen dit de Red Light Zone, iets dat een AI misschien wel kan maar dat mensen niet willen. Dat percentage is nog hoger in de Arts, Designs, and Media-sector, namelijk 48%
Goed nieuws
Cloudflare gaat een AI-blokker implementeren, zodat je jezelf makkelijker kan beschermen tegen datascrapers. Jammer dat het juridische pad steeds niks oplevert, maar dit is in ieder geval iets. Over juridisch gesproken, in de (verder vrij ellendige) Big Beautiful Bill is het stuk dat Amerikaanse staten zou verbieden om AI te reguleren, gelukkig geschrapt.
En ik had het even gemist, dit nieuws van midden juni, maar SIVON, de ICT coöperatie waarbij meer dan 400 schoolbesturen zijn aangesloten, gaat starten met een Open Source pilot! Ben je schoolbestuurder, dan kan je je via de link meteen aanmelden, ben je leraar moedig dan je schoolbestuur aan om ook mee te doen.
Fijne zomer, geniet van je boterham in het zonnetje!
[[1]]: Voor podcasts gaat dit argument ten dele ook op, zoals Anil Dash vorig jaar schreef “Wherever you get your podcasts” is a radical statement. Maar, podcasts zijn natuurlijk wel veel meer verweven met big tech dan nieuwsbrieven.
Member discussion